-
Kết nối dữ liệu từ nhiều nguồn
-
Cài đặt Python và R
-
Xử lý làm sạch dữ liệu với Tableau Prep
-
Khám phá Tài nguyên dành cho Nhà phát triển
Python lấy dữ liệu API nâng cao – với nhiều cấp con
Vẫn với chức năng của Pokemon ta có API sau: https://pokeapi.co/api/v2/ability/1
Cấu trúc phân cấp như hình
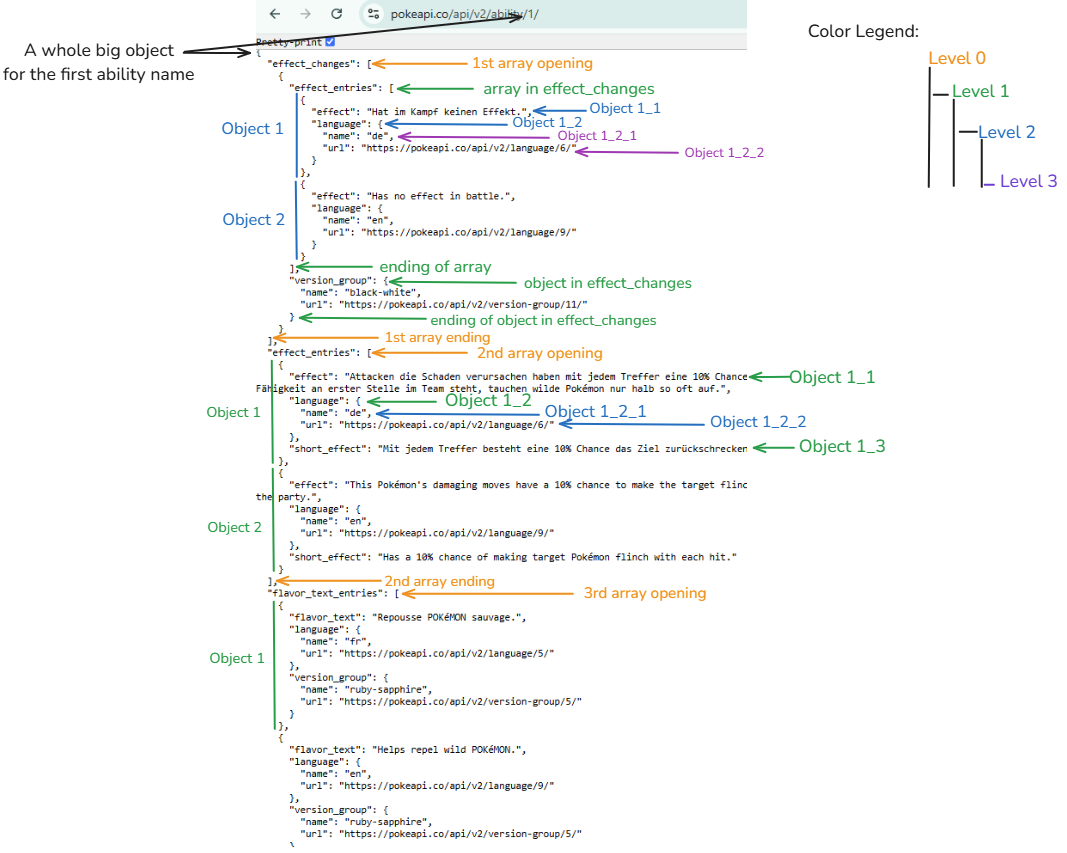
Từ thao tác lấy API tại bước cơ bản ta được 1 bộ dữ liệu như dưới đây

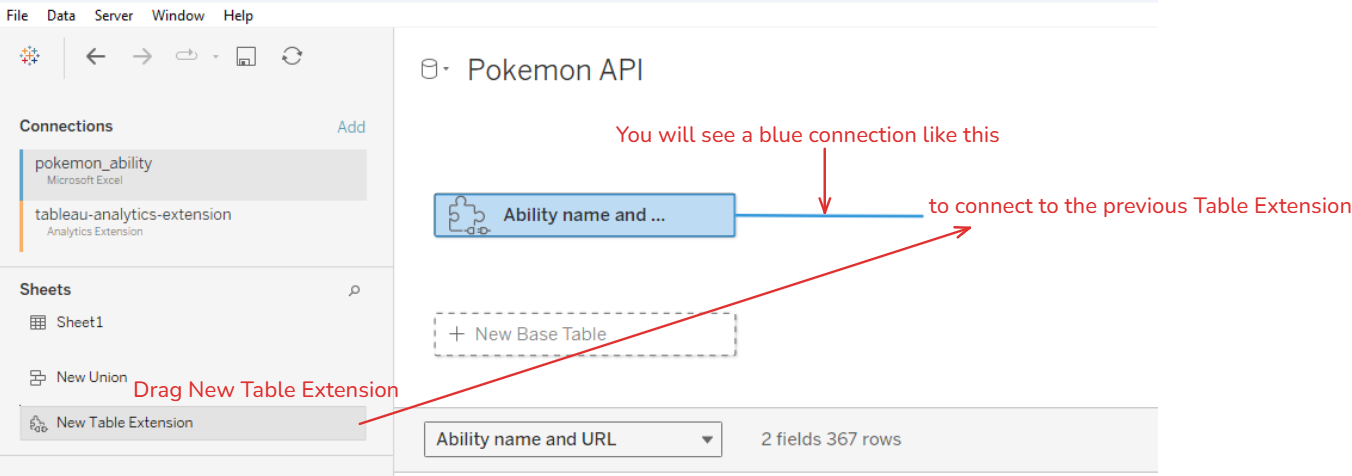
Thực hiện kéo thêm 1 Extension mới vào canvas để nối với API đầu tiên
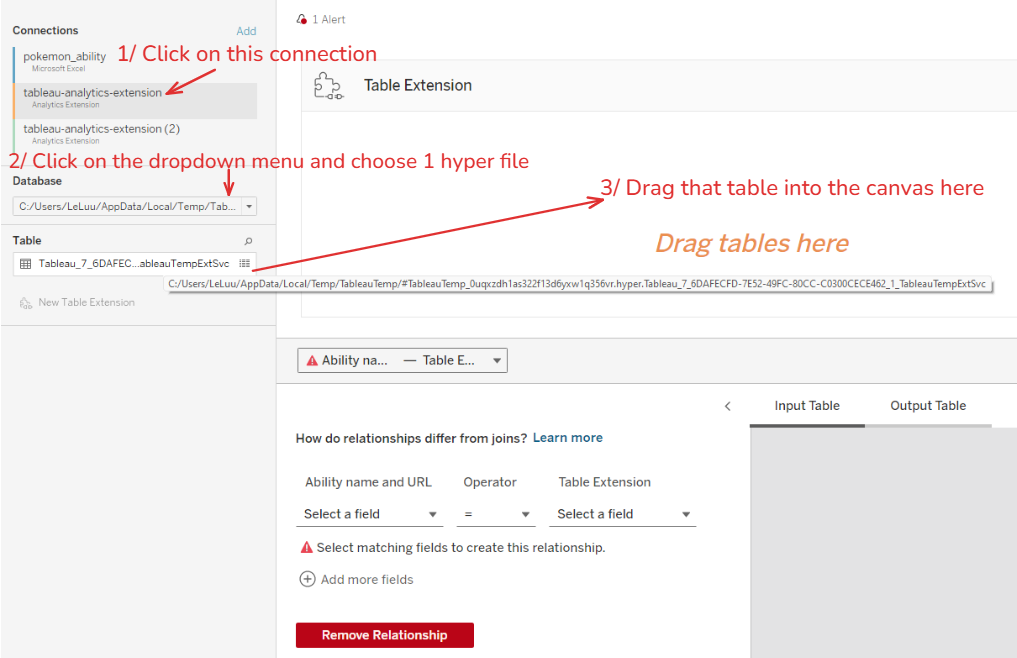
Lúc này bên trái xuất hiện bảng dữ liệu dầu ra của API 1 là tableau-analytics-extension, ta bấm chọn để hiển thị tuỳ chỉnh Database và table phù hợp. Ta chọn bảng tạm đó kéo vào canvas
Thực hiện nhập đoạn code để lấy dữ liệu phù hợp
import pandas as pd
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
# Định nghĩa hàm parse_json_from_url
def parse_json_from_url(ability_name, url):
try:
res = requests.get(url, timeout=5)
res.raise_for_status()
data = res.json().get(‘effect_changes’)
print(f”Fetched data for {url}: {data}”) # Ghi log để kiểm tra dữ liệu
except (requests.exceptions.RequestException, ValueError) as e:
print(f”Error fetching/parsing {url}: {e}”)
return pd.DataFrame() # Trả về DataFrame rỗng nếu có lỗi
if not data:
print(f”No ‘effect_changes’ data for {url}”)
return pd.DataFrame()
try:
df = pd.json_normalize(
data,
record_path=’effect_entries’,
meta=[‘version_group’],
record_prefix=’effect_entries_’
)
df[[‘version_name’, ‘version_url’]] = pd.json_normalize(df[‘version_group’])
df = df.drop(columns=[‘version_group’])
df[‘ability_name’] = ability_name
df[‘ability_url’] = url
print(f”Processed DataFrame for {url}: {df.shape}”) # Ghi log kích thước DataFrame
return df
except Exception as e:
print(f”Error normalizing data for {url}: {e}”)
return pd.DataFrame()
# Kiểm tra và gán data_df từ _arg1
try:
data_df = pd.DataFrame(_arg1) if ‘_arg1’ in globals() and _arg1 is not None else pd.DataFrame()
print(f”Input data_df shape: {data_df.shape}, columns: {data_df.columns}”) # Ghi log thông tin data_df
except Exception as e:
print(f”Error initializing data_df from _arg1: {e}”)
data_df = pd.DataFrame()
# Tạo danh sách trống để lưu trữ dữ liệu
df_list = []
# Kiểm tra nếu data_df có dữ liệu
if not data_df.empty and ‘name’ in data_df.columns and ‘url’ in data_df.columns:
print(f”Processing {len(data_df)} rows from data_df”)
# Sử dụng ThreadPoolExecutor để gửi yêu cầu song song
with ThreadPoolExecutor(max_workers=10) as executor:
# Tạo danh sách các tác vụ
futures = [executor.submit(parse_json_from_url, row[‘name’], row[‘url’]) for _, row in data_df.iterrows()]
# Thu thập kết quả
for future in as_completed(futures):
result = future.result()
if not result.empty:
df_list.append(result)
else:
print(“data_df is empty or missing required columns ‘name’ and ‘url'”)
# Nối các DataFrame thành một tập dữ liệu đầy đủ
if df_list:
full_data = pd.concat(df_list, ignore_index=True)
print(f”Final full_data shape: {full_data.shape}”)
else:
# Nếu không có dữ liệu, trả về một DataFrame rỗng với các cột cố định
print(“No data collected, returning empty DataFrame with predefined columns”)
full_data = pd.DataFrame(columns=[
‘effect_entries_effect’, ‘effect_entries_language.name’, ‘effect_entries_language.url’,
‘effect_entries_short_effect’, ‘version_name’, ‘version_url’, ‘ability_name’, ‘ability_url’
])
return full_data
Đoạn code trên sẽ ko ra input nếu chưa thiết lập mối quan hệ 2 kết nối là cột name và ability_name
Tạo thêm các extéasion tương tự để lấy nối dữ liệu tại effect change và Plavor text Entries